Installation de Torque sur Ubuntu 14.04
Posted on Sat 10 October 2015 in misc
 Torque est un gestionnaire de ressources et un
gestionnaire de travaux par lot (batch). Torque réceptionne les demandes
de travaux auprès des utilisateurs, les places en file d'attente, il
peut gérer la disponibilité des noeuds de calcul du cluster et
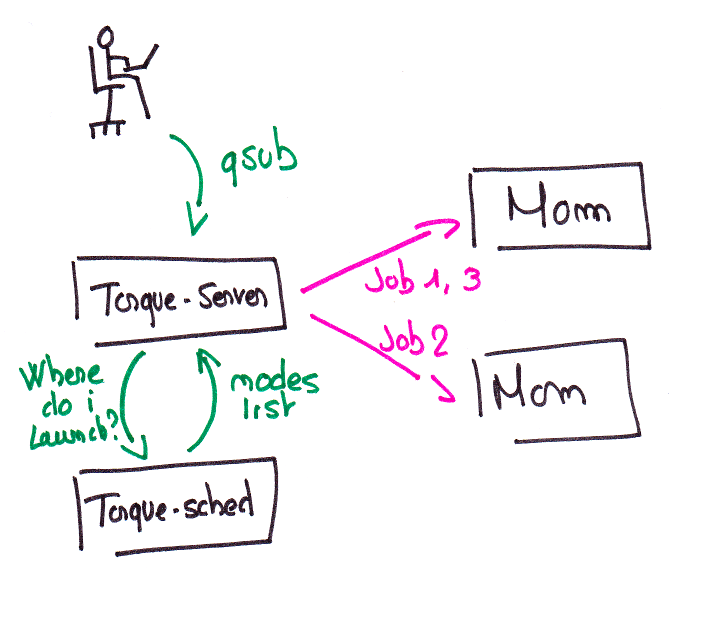
distribuer les tâches. Torque est composé de 3 types de services;
torque-server (pbs-server) reçoit les demandes des utilisateurs
(soumissions, stats...), scheduler donne au server les noeuds sur
lequelles envoyer les jobs et enfin, les MOMs, installées sur les noeuds
de calcul, executent les jobs et informent le server sur le
fonctionnement des jobs. Torque est open-source, porté par la société
Adaptive Computing et très bien documenté, de plus amples informations
peuvent être trouvées sur leur site
internet.
Torque est un gestionnaire de ressources et un
gestionnaire de travaux par lot (batch). Torque réceptionne les demandes
de travaux auprès des utilisateurs, les places en file d'attente, il
peut gérer la disponibilité des noeuds de calcul du cluster et
distribuer les tâches. Torque est composé de 3 types de services;
torque-server (pbs-server) reçoit les demandes des utilisateurs
(soumissions, stats...), scheduler donne au server les noeuds sur
lequelles envoyer les jobs et enfin, les MOMs, installées sur les noeuds
de calcul, executent les jobs et informent le server sur le
fonctionnement des jobs. Torque est open-source, porté par la société
Adaptive Computing et très bien documenté, de plus amples informations
peuvent être trouvées sur leur site
internet.
Ce billet explique l'installation de Torque sur une installation de 3 noeuds sur le système d'exploitation Linux Ubuntu 14.04.
Il nous faut donc 3 machines (au minimum 2, on peut se passe d'un worker).
- cluster-manager : Noeud de soumission, serveur et scheduler Torque
- cluster-worker-1 : Noeud de calcul (MOM)
- cluster-worker-2 : Noeud de calcul (MOM)
Cinématique de Torque
Installation de Torque
Sur cluster-manager.
Torque est packagé pour la Ubuntu 14.04, il s'agit d'une version relativement ancienne mais pour le test, par besoin de killer-features disponibles dans les suivantes.
L'installation de Torque server et scheduler est donc simple
apt-get install torque-server torque-scheduler torque-client
Le paquetage créé une configuration de base (que je vais m'empresser d'écraser). Le TORQUE_HOME se trouve être /var/spool/torque.
Remise à zéro de la configuration
On arrête les services
service torque-scheduler stopservice torque-server stop
Et on se sert de la commande pbs_server -t create pour reppartir d'un configuration de base (répondre Yes).
pbs_server -t create PBS_Server cluster-manager.novalocal: Create mode and server database exists, do you wish to continue y/(n)
Pour que le client fonctionne, il faut signaler que le server est cluster-manager.
echo $HOSTNAME > /etc/torque/server_name
Configuration du serveur pbs
On entre dans le shell intéractif de configuration avec la commande qmgr. Puis on configure quelques paramètres :
set server scheduling = True set server acl_hosts = cluster-manager set server managers = root@cluster-manager set server operators = root@cluster-manager set server auto_node_np = True
Création de la file d'attente
Nous allons créer une file d'attente nommée jobq de type execution. Si lors de la soumission du job rien n'est précisé, les jobs auront une durée maximale de 1 minutes (walltime) et tournerons sur 2 noeuds (nodes).
create queue jobq set queue jobq queue_type = Execution set queue jobq resources_default.nodes = 2 set queue jobq resources_default.walltime = 00:01:00 set queue jobq enabled = True set queue jobq started = True
Et on configure cette file comme file par défaut
set server default_queue = jobq
Nous allons maintenant pouvoir intégrer les noeuds de calcul, même si ceux ci ne sont pas configuré. Il faut veiller a ce que les noeuds se connaissent (/etc/hosts ou dns).
create node cluster-worker-1 create node cluster-worker-2
On peux préciser des informations supplémentaires sur les noeuds (nombre de cpus par exemple). Nous avons ici choisi de laisser le serveur découvrir le nombre de CPUs disponibles (set server auto_node_np = True).
Sur les noeuds de calcul
Installation du service MOM
aptitude install torque-mom
echo "cluster-manager" > /etc/torque/server_name service torque-mom restart
Vérification des logs dans /var/spool/torque/mom_logs/20151011
tail /var/spool/torque/mom_logs/20151011 10/11/2015 06:37:35;0002; pbs_mom;Svr;pbs_mom;Torque Mom Version = 2.4.16, loglevel = 0 10/11/2015 06:37:35;0001; pbs_mom;Svr;pbs_mom;LOG_ERROR::No such file or directory (2) in read_config, fstat: config 10/11/2015 06:37:35;0002; pbs_mom;Svr;setpbsserver;cluster-manager 10/11/2015 06:37:35;0002; pbs_mom;Svr;mom_server_add;server cluster-manager added 10/11/2015 06:37:35;0002; pbs_mom;n/a;initialize;independent 10/11/2015 06:37:35;0080; pbs_mom;Svr;pbs_mom;before init_abort_jobs 10/11/2015 06:37:35;0002; pbs_mom;Svr;pbs_mom;Is up 10/11/2015 06:37:35;0002; pbs_mom;Svr;setup_program_environment;MOM executable path and mtime at launch: /usr/sbin/pbs_mom 1387280091 10/11/2015 06:37:35;0002; pbs_mom;Svr;pbs_mom;Torque Mom Version = 2.4.16, loglevel = 0 10/11/2015 06:37:35;0002; pbs_mom;n/a;mom_server_check_connection;sending hello to server cluster-manager
Vérification de l'enregistrement des noeuds sur le manager
pbsnodes -a
cluster-worker-1 state = free np = 2 ntype = cluster status = rectime=1444545757,varattr=,jobs=,state=free,netload=1041862,gres=,loadave=0.00,ncpus=2,physmem=2049832kb,availmem=4083056kb,totmem=4146980kb,idletime=1853,nusers=0,nsessions=? 0,sessions=? 0,uname=Linux cluster-worker-1 3.13.0-53-generic #89-Ubuntu SMP Wed May 20 10:34:39 UTC 2015 x86_64,opsys=linux cluster-worker-2 state = free np = 2 ntype = cluster status = rectime=1444545761,varattr=,jobs=,state=free,netload=959154,gres=,loadave=0.00,ncpus=2,physmem=2049832kb,availmem=4083176kb,totmem=4146980kb,idletime=1862,nusers=0,nsessions=? 0,sessions=? 0,uname=Linux cluster-worker-2 3.13.0-53-generic #89-Ubuntu SMP Wed May 20 10:34:39 UTC 2015 x86_64,opsys=linux
Soumettons (nous à) un test
Préparation du test
Il faut un utilisateur lambda, pas root.
Ensuite deux cas :
- l'utilisateur dispose d'un répertoire home partagé et disponible sur les noeuds de soumission et de calcul. C'est le cas classique dans un centre de calcul (serveur NFS, LDAP/NIS)
- L'utilisateur n'en dispose pas. Cela nécessite alors une connexion SSH bi-directionnelle, sans mot de passe et sans dialogue. En clair, l'utilisateur doit pouvoir faire des ssh dans tous les sens sans mot de passe.
Je suis dans le cas n° 2, alors...
Sur chaque machine, on remplit le fichier /etc/ssh/ssh_known_hosts afin que ssh ne demande pas aux utilisateurs de confirmer la clef. Gérer ce fichier via Puppet ou un équivalent sera utile si le cluster contient beaucoup de noeuds.
ssh-keyscan cluster-manager >> /etc/ssh/ssh_known_hosts ssh-keyscan cluster-worker-1 >> /etc/ssh/ssh_known_hosts ssh-keyscan cluster-worker-2 >> /etc/ssh/ssh_known_hosts
Ensuite, pour tester, on ajoute un utilisateur sur toutes les machines.
useradd -m tristanlt passwd tristanlt usermod -s /bin/bash
Sur l'une machine (manager par exemple), on va créer une clef ssh sans passphrase (afin de garantir des ssh automatiques). Nous copierons ensuite les fichiers contenus dans le dossier .ssh de l'utilisateur sur les autres machines. (inutile si le home de l'utilisateur est partagé)
su tristanlt - ssh-keygen -t ecdsa Generating public/private ecdsa key pair. Enter file in which to save the key (/home/tristanlt/.ssh/id_ecdsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/tristanlt/.ssh/id_ecdsa. Your public key has been saved in /home/tristanlt/.ssh/id_ecdsa.pub. [...]
Puis on copie les fichiers sur les autres machines. (ici, la clef a été fabriquée sur le manager)
scp .ssh/* tristanlt@cluster-worker-1:.ssh/ scp .ssh/* tristanlt@cluster-worker-2:.ssh/
Ready ?
Ce billet ne traite pas de l'écriture de fichier PBS. On trouve énormément de documentation sur l'écriture de tel fichier. Voici celui que j'ai utilisé ( commentaire dans le texte ):
#!/bin/bash
# On créé 3 jobs, 20 21 et 22
#PBS -t 20-22
# On demande un noeud et 2 CPU
#PBS -l nodes=1:ppn=2
# Le temps maximum est estimé à 10mn
#PBS -l walltime=00:10:00
# Les deux lignes suivantes crée un fichier de logs dans lequel se trouve Output o et Error e
#PBS -o sleepjob.log
#PBS -j oe
cd /home/tristanlt
# On attend la durée de 20, 21 ou 22 secondes (selon le array ID)
sleep $PBS_ARRAYID
echo "Running on ${HOSTNAME} ArrayID ${PBS_ARRAYID}"
Le job, ici dans un fichier nommé sleepjob.pbs se soumet à partir de cluster-manager grâce à la commande :
qsub sleepjob.pbs
Ensuite, nous pouvons consulter l'avancement grâce à la commande qstat
qstat Job id Name User Time Use S Queue ------------------------- ---------------- --------------- -------- - ----- 22-20.cluster-manager sleepjob.pbs-20 tristanlt 0 R jobq 22-21.cluster-manager sleepjob.pbs-21 tristanlt 0 R jobq 22-22.cluster-manager sleepjob.pbs-22 tristanlt 0 Q jobq
Dans le cas suivant, lors de l'exécution de la tâche, 20 et 21 étaient Running (R) et 22 était en file d'attente (Q).
Il ne reste plus qu'a regarder les fichiers de log du job pour admirer le résultat du script d'attente le plus compliqué que j'ai jamais écrit. Reste plus qu'a faire des trucs intelligents avec... Là je vous laisse faire le boulot.